Artificial Intelligence
Artificial Intelligences - Machine Learning - Deep Learning
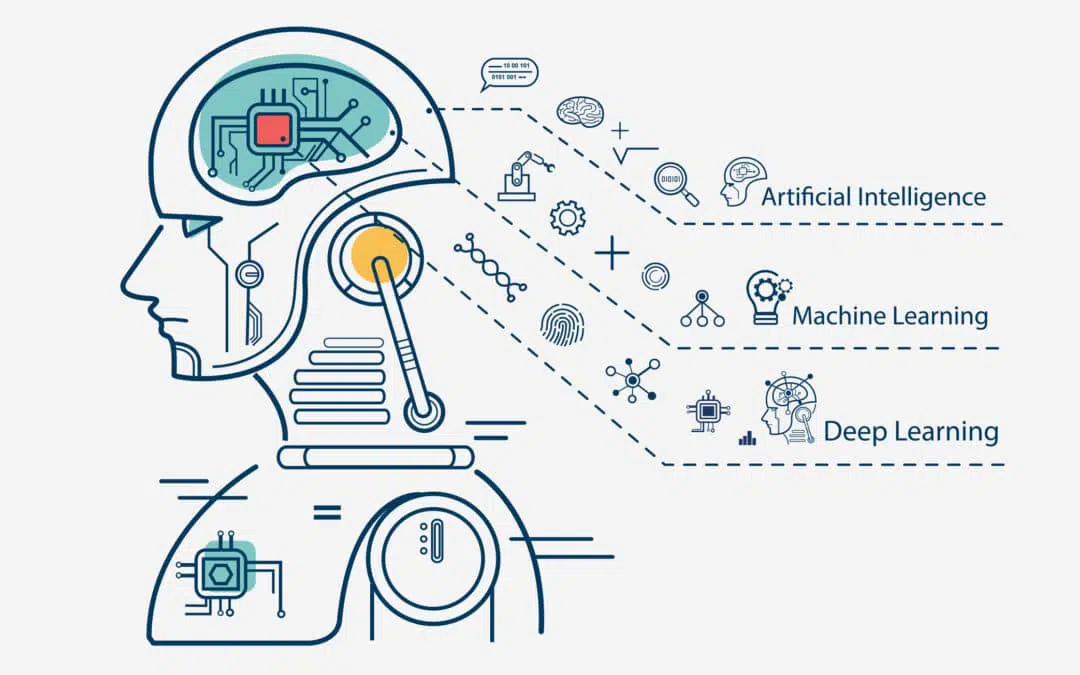
Machine learning (ML) is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy.
Deep Learning (DP) is a type of machine learning based on artificial neural networks in which multiple layers of processing are used to extract progressively higher-level features from data.
Some benefits that companies can obtain from AI/ML/DP
Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) offer a plethora of benefits across multiple domains:
- Enhanced Automation: These technologies automate tasks, reducing human effort and errors in various industries, leading to increased efficiency and productivity.
- Data Analysis and Insights: AI, ML, and DL can analyze vast amounts of data to uncover patterns, trends, and correlations that humans might miss, enabling data-driven decision-making in fields like finance, healthcare, and marketing.
- Improved Efficiency and Cost Savings: Automation and optimization through AI/ML/DL lead to cost reductions and operational efficiencies in processes, resource utilization, and supply chain management.
- Personalization and Customer Experience: They enable personalized experiences and recommendations in e-commerce, content delivery, and customer service, enhancing user satisfaction and engagement.
- Healthcare Advancements: AI/ML/DL aid in disease diagnosis, drug discovery, personalized medicine, and health monitoring, revolutionizing patient care and treatment.
- Enhanced Security and Fraud Detection: These technologies help in identifying anomalies, preventing fraud in finance, cybersecurity breaches, and ensuring system security through predictive analytics.
- Predictive Maintenance and Optimization: AI/ML/DL models predict equipment failure, optimize maintenance schedules, and enhance operational efficiency in industries such as manufacturing and utilities.
- Natural Language Processing and Understanding: Advancements in NLP through AI/ML/DL facilitate language translation, sentiment analysis, chatbots, and voice assistants, improving communication and accessibility.
- Innovation and Creativity: AI-driven tools assist in creative tasks like art generation, music composition, and content creation, augmenting human capabilities and fostering innovation.
- Environmental Impact: AI/ML/DL can optimize energy usage, resource allocation, and aid in climate modeling and forecasting, contributing to sustainability efforts.
These benefits, however, come with ethical considerations regarding data privacy, bias, transparency, and the responsible deployment of AI systems. Balancing technological advancements with ethical considerations is crucial for harnessing the full potential of these technologies.
The Learning Process
There are five steps in the Learning Process. The first two steps are shared with the Data Science methodology, which are Data Gathering and Data Cleaning. Feature Extraction, Model Training, and Prediction are specific tasks for ML/DP Projects.

Data Gathering
This Machine Learning process is based on the first step of the Data Science step. And just like the name states, it is simply the step where we obtain all available data needed from various data sources.
Data Cleaning
The real-world data is not perfect, sometimes the data is mistakenly placed, missing, or invalid. Data cleaning is the process of identifying and removing (or correcting) inaccurate records from a dataset, table, or database and refers to recognizing unfinished, unreliable, inaccurate, or non-relevant parts of the data and then restoring, remodeling, or removing the dirty or crude data.
Data cleaning techniques may be performed as batch processing through scripting or interactively with data cleansing tools.

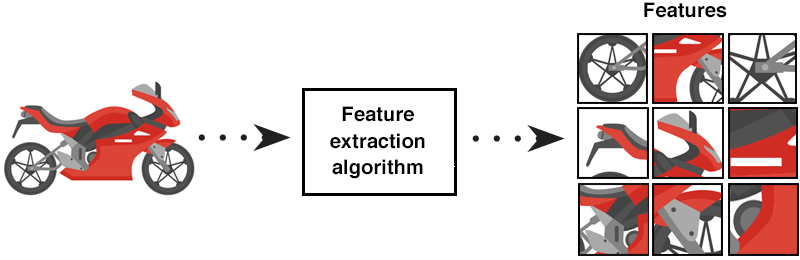
Feature Extraction
Feature extraction is a technique used to reduce a large input data set into relevant features. This is done with dimensionality reduction to transform large input data into smaller, meaningful groups for processing.
This step also involves Feature Engineering, in which you use the domain knowledge of the data to transform it into the features which would improve the accuracy of your Machine Learning model.
Model Training
This is the main step in which the Machine Learning model is actually built by using a particular algorithm and inputting training data from the previous step. Depending upon the size of the data, the type of algorithm used, and/or the hardware on which it is run, this step can take anywhere from a few minutes to hours to learn the model.

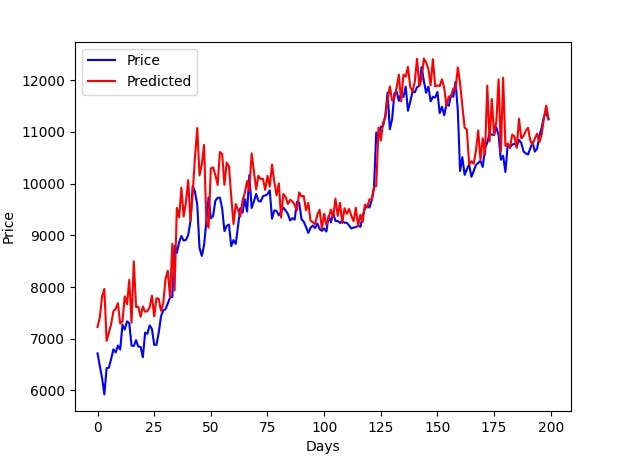
Prediction
The final step of the pipeline is to evaluate the performance of the model you just trained. If the performance of the model does not meet the acceptance criteria, then the model needs to be retrained again with the updated information. Model Training and Predictions steps often have to be repeated back and forth multiple times before a good enough model can be trained.
We utilize open-source, proprietary, and licensed libraries to help you achieve your objectives. We determine the ideal solution for your requirements.





